Technologies bloquantes en SEO : les freins qui empêchent Google d’indexer votre site
Une technologie est dite bloquante en SEO lorsqu’elle empêche Googlebot d’explorer, de rendre ou d’indexer tout ou partie des pages d’un site web, indépendamment de la qualité du contenu. La conséquence principale est une invisibilité partielle ou totale dans les résultats de recherche et, depuis 2026, dans les réponses générées par les LLMs.
Note : voici les erreurs courantes qu’on voit le plus souvent : le fichier robots.txt, le rendu JavaScript côté client (CSR), les redirections en chaîne, les erreurs serveur 5xx et certaines configurations CMS qui génèrent des URLs parasites ou bloquent des ressources critiques.
Au programme :
Ce qu’on entend par « technologie bloquante » en SEO
Une technologie bloquante n’est pas nécessairement un bug. C’est souvent une configuration par défaut, un choix d’architecture ou une balise oubliée en production qui coupe court au travail de Googlebot sans alerte visible dans l’interface.
La distinction entre frein d’exploration et frein d’indexation
La documentation Google Search Central formalise cette séquence en deux phases distinctes : Googlebot crawle d’abord le HTML brut (exploration), puis place la page dans une rendering queue avant d’exécuter le JavaScript via Chromium headless (rendu / indexation). Le délai entre ces deux phases peut aller de quelques secondes à plusieurs jours. Un blocage intervenu à la première étape ne laisse aucune chance à la seconde.
Un robots.txt mal configuré bloque le crawl : Googlebot ne peut pas accéder à la page. Une balise noindex bloque l’indexation : Googlebot accède à la page, mais refuse de la référencer. Ces deux problèmes se corrigent différemment. Les confondre revient à traiter le mauvais chantier.
Les technologies bloquantes côté infrastructure
robots.txt : la directive qui peut tout fermer d’un coup
Une directive Disallow: / dans le fichier robots.txt exclut l’intégralité du site de l’exploration en quelques heures. C’est l’erreur la plus grave en SEO technique : silencieuse, immédiate, et parfois introduite par un développeur pendant une mise en recette.
Les cas les plus fréquents : blocage accidentel des dossiers /wp-admin/, /wp-content/ (si vous êtes sur WordPress) ou de ressources CSS/JS nécessaires au rendu. Googlebot ne peut alors pas évaluer la mise en page — ce qui affecte directement le score de rendu et les Core Web Vitals.
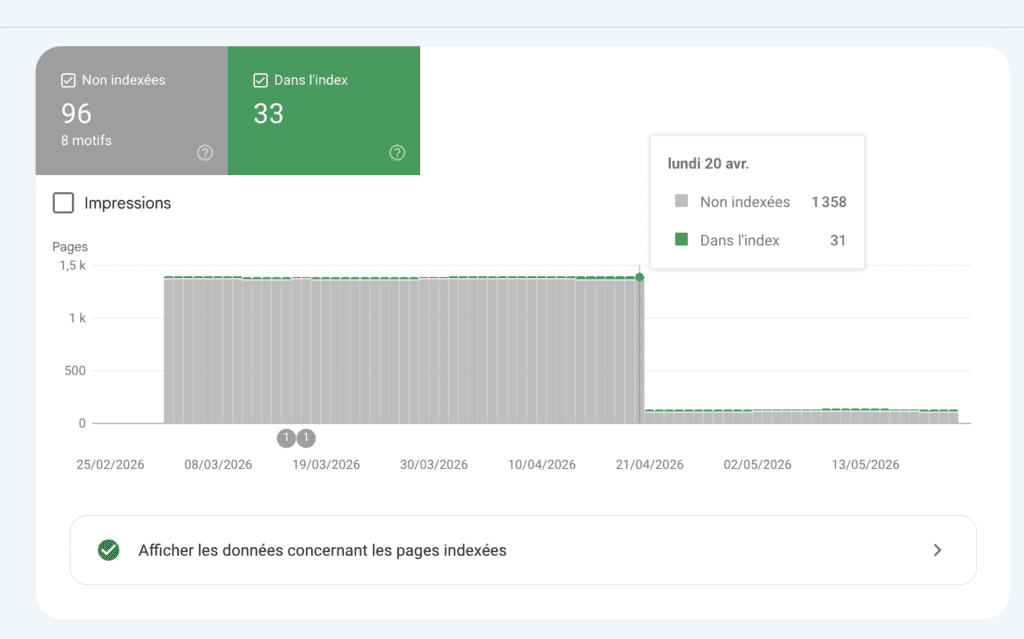
Vérification : Google Search Console > Inspection d’URL > « URL non disponible pour Google ».
Pour le site de GJ formations, un simple contrôle à permis de remarquer que plus de 1300 pages existaient mais n’étaient pas vues par Google !
A force de désindexer, le budget crawl du client (=fréquence à laquelle le GoogleBot passe sur le site) était devenu très bas ce qui est synonyme d’un site en perdition. Si Les moteurs de recherche ne prennent pas la peine d’y envoyer leurs robots pour vous y référencer, c’est la mort de votre site web !
Redirections en chaîne et erreurs 5xx
On le mentionnait juste avant mais le crawl budget : chaque redirection supplémentaire que vous faites sur votre site consomme en consomme une partie Une chaîne de trois redirections ou plus sur des URLs fréquemment crawlées dilue le budget d’exploration disponible pour le reste du site. Les boucles de redirection (A → B → A) génèrent un timeout immédiat.
Les erreurs serveur 5xx ont le même effet : Googlebot abandonne l’URL après plusieurs tentatives infructueuses et la désindexe progressivement si l’erreur persiste. Screaming Frog (version gratuite) permet de cartographier les chaînes de redirection et d’isoler les 5xx actifs sur un domaine.
HTTPS mal configuré = message d’un site mal sécurisé, un ennemi pour les robots
Un certificat SSL actif ne garantit pas que l’ancienne version HTTP est correctement redirigée. Si la redirection 301 de http:// vers https:// est absente ou incomplète, Google peut maintenir deux versions du site dans son index — avec des signaux canoniques contradictoires. La balise canonique devient alors le seul garde-fou, à condition qu’elle pointe systématiquement vers la version HTTPS.
JavaScript côté client : le frein le plus sous-estimé
Pourquoi certains sites restent invisibles pour Google
Sur certains sites, quand un robot arrive, il trouve une page blanche. Le contenu n’est pas encore là, il se construit quelques milisecondes plus tard, mais il est déjà reparti.
C’est exactement ce qui se passe avec les sites construits sur des technologies modernes mal configurées. Google visite, ne voit rien, et doit revenir plus tard. Ce délai peut durer de quelques secondes à plusieurs jours. Pendant ce temps, la page n’apparaît pas dans les résultats.
Les moteurs IA (ChatGPT, Perplexity…) ont le même problème en pire : ils ne reviennent jamais. Ce qu’ils ne voient pas à la première visite, ils ne le citent pas.
Ce que ça change selon la technologie du site
Comment le site est construit
Google voit le contenu ?
Les IA le citent ?
Adapté pour…
Contenu construit par le navigateur
⚠️ Pas toujours, pas tout de suite
❌ Non
Outils internes, espaces privés
Contenu préparé par le serveur avant envoi
✅ Oui, dès la première visite
✅ Oui
Sites mis à jour régulièrement
Pages préparées une fois, servies telles quelles
✅ Optimal
✅ Idéal
Sites vitrine, blogs
En bref, Google lit d’abord le HTML de votre site, c’est le fichier de base, celui qui contient le texte brut de vos pages. Le JavaScript, lui, est une couche supplémentaire qui s’exécute ensuite. Si votre site repose entièrement sur JavaScript pour afficher son contenu, Google arrive souvent sur une page HTML vide. Il peut revenir plus tard pour attendre que JavaScript ait fini son travail, mais ce n’est pas garanti et les moteurs IA, eux, ne reviennent jamais.
Ce qu’il faut retenir : si votre site est un outil interne ou un espace client, peu importe. Si votre site est censé être trouvé par Google ou par une IA, il doit livrer son contenu immédiatement, sans délai de construction. C’est une décision technique qui se prend à la création du site, ou lors d’une refonte.
Les technologies CMS et leur impact sur la crawlabilité
URLs paramétrées et contenu dupliqué généré automatiquement
Certains CMS génèrent automatiquement des centaines d’URLs paramétrées (?page=2, ?sort=prix, ?color=rouge) qui dupliquent le contenu existant sans valeur ajoutée. Le crawl budget est alors absorbé par des URLs sans pertinence SEO, au détriment des pages stratégiques.
Les CMS à architecture fermée type Wix posent un problème structurel supplémentaire : ils délèguent la gestion des URLs, des redirections et du rendu à leur propre infrastructure, ce qui ralentit mécaniquement l’exploration et l’apparition dans les résultats. La personnalisation du robots.txt y est partielle, et certaines ressources JS restent hors de portée de l’auditeur..
Ressources CSS/JS bloquées au niveau du robots.txt CMS
WordPress et d’autres CMS peuvent générer un robots.txt qui bloque par défaut des répertoires contenant des ressources de rendu (/wp-content/plugins/, /assets/). Googlebot ne peut alors pas évaluer la mise en page réelle de la page — ce qui affecte les signaux de rendu et, indirectement, les Core Web Vitals (LCP, INP, CLS).
Vérification : outil de test robots.txt dans Google Search Console + rapport « Ressources bloquées » dans l’inspection d’URL.
Comment prioriser les corrections — la grille de triage
Type de blocage
Impact sur l’indexation
Priorité de correction
Disallow global dans robots.txt
Critique — exclusion totale du crawl
P0 — immédiat
Balise noindex laissée en production
Critique — page explorée, non indexée
P0 — immédiat
JavaScript CSR sur pages stratégiques
Élevé — contenu invisible au premier crawl
P1 — sprint suivant
Erreurs 5xx récurrentes
Élevé — désindexation progressive
P1 — sprint suivant
Redirections en chaîne (3+)
Modéré — perte de crawl budget
P2 — planifié
URLs paramétrées sans canonique
Modéré — dilution du budget d’exploration
P2 — planifié
HTTPS/HTTP non unifié
Modéré — signaux canoniques contradictoires
P2 — planifié
Ressources CSS/JS bloquées
Faible à modéré — impact sur rendu
P3 — backlog
Robots.txt sans directives IA
Variable — invisibilité dans les LLMs
P1 si GEO prioritaire
Règle de priorisation : les bloqueurs d’accès (robots.txt, noindex involontaire) passent avant les bloqueurs de rendu (JavaScript CSR), qui passent avant les bloqueurs de signal (redirections, canoniques incohérentes).
L’angle crawlers IA : un blocage silencieux à auditer dès maintenant
Les robots.txt sont désormais lus par une nouvelle génération de crawlers : GPTBot (OpenAI), PerplexityBot, ClaudeBot (Anthropic). Selon les données Cloudflare publiées en janvier 2026, GPTBot a enregistré une hausse de 305 % en volume de requêtes entre mai 2024 et mai 2025, et représente désormais le crawler IA dominant. Seuls 14 % des 10 000 premiers domaines mondiaux ont des directives robots.txt ciblant explicitement ces bots.
En 2025-2026, un robots.txt bloquant GPTBot ou PerplexityBot produit le même effet qu’un noindex pour les moteurs traditionnels : invisibilité totale dans les réponses générées par les LLMs.
Ce qu’il faut auditer : vérifier que les directives User-agent: GPTBot et User-agent: PerplexityBot n’incluent pas de Disallow: / non intentionnel. La documentation Google sur l’optimisation pour l’IA (AI Optimization Guide) précise par ailleurs que la lisibilité du HTML brut est une condition préalable à la citation dans les AI Overviews — ce qui renforce la priorité du SSR/SSG sur le CSR pour les pages à fort enjeu éditorial.
Pour aller plus loin
Qu’est-ce qu’une technologie bloquante en SEO ?
Une technologie est dite bloquante en SEO lorsqu’elle empêche Googlebot d’explorer, de rendre ou d’indexer tout ou partie des pages d’un site web. Les principales causes sont un fichier robots.txt mal configuré, une balise noindex laissée en production, un rendu JavaScript côté client, des redirections en chaîne ou des erreurs serveur récurrentes.
Comment savoir si mon site est bloqué pour Google ?
Google Search Console permet de diagnostiquer les blocages via l’outil d’inspection d’URL et le rapport de couverture d’index. Screaming Frog permet d’auditer les redirections en chaîne, les erreurs serveur et les ressources bloquées au niveau du robots.txt.
JavaScript est-il mauvais pour le SEO ?
Le JavaScript lui-même n’est pas problématique, mais le rendu côté client l’est. Googlebot place les pages JavaScript dans une file d’attente avant de les traiter, avec un délai pouvant aller de quelques secondes à plusieurs jours. Les architectures SSR ou SSG résolvent ce problème en servant un HTML complet dès l’exploration initiale.
Comment corriger un robots.txt qui bloque l’indexation ?
Accéder au fichier robots.txt via votre-domaine/robots.txt et identifier toute directive d’exclusion trop large. Corriger en limitant les exclusions aux répertoires réellement à protéger comme les espaces admin ou de staging. Vérifier ensuite via l’outil de test robots.txt dans Google Search Console que les URLs stratégiques sont bien accessibles.
Quelle est la différence entre crawl et indexation en SEO ?
Le crawl est la phase d’exploration : Googlebot accède à l’URL et lit le HTML brut. L’indexation est la phase suivante : Googlebot rend la page, exécute le JavaScript, et décide de l’intégrer ou non à son index. Un robots.txt bloque le crawl ; une balise noindex bloque l’indexation. Ces deux blocages se produisent à des étapes différentes et se corrigent différemment.
Article rédigé par Aymeric Favry, consultant SEO. Données issues de projets clients 2024-2026 (Search Console).
Ressource gratuite
On a enfin trouvé le moyen de rédiger des articles que Google et les IA voient vraiment.
Le brief d'article Perfoseos : 6 champs, 5 minutes, un brief prêt à coller dans Claude ou ChatGPT.
Pas de démarchage. Juste le fichier.
Bien reçu, vous devriez recevoir votre template dans quelques minutes !
Et si vous souhaitez savoir concrètement ce qui bloque sur votre site web, c'est ici
Diagnostic express · 2 minutes
Estimation de potentiel SEO
4 questions simples pour estimer un ordre de grandeur. Pas besoin de jargon.
Question 1/4Répondez au plus proche de votre situation.
Estimation indicative — ordre de grandeur. Aucun outil ni accès technique requis.